¡Bienvenidos a nuestro Blog!
Espero puedan disfrutarlo y aprender.
Este será un contacto que podrá superar los límites de tiempo de las horas de clase: aprovéchenlo para construir algo nuevo.
Debido a que las estructuras de datos son utilizadas para almacenar
información, para poder recuperar esa información de manera eficiente es
deseable que aquella esté ordenada. Existen varios métodos para ordenar
las diferentes estructuras de datos básicas. En general los métodos de ordenamiento no son utilizados con frecuencia,
en algunos casos sólo una vez. Hay métodos muy simples de implementar
que son útiles en los casos en dónde el número de elementos a ordenar no
es muy grande (ej, menos de 500 elementos). Por otro lado hay métodos
sofisticados, más difíciles de implementar pero que son más eficientes
en cuestión de tiempo de ejecución.
Los métodos sencillos por lo general requieren de aproximadamente n x n pasos para ordenar n elementos.
Los métodos simples son: insertion sort (o por inserción directa)
selection sort, bubble sort, y shellsort, en dónde el último es una
extensón al insertion sort, siendo más rápido. Los métodos más complejos
son el quick-sort, el heap sort, radix y address-calculation sort.
El ordenar un grupo de datos significa mover los datos o sus referencias
para que queden en una secuencia tal que represente un orden, el cual
puede ser numérico, alfabético o incluso alfanumérico, ascendente o
descendente.
Se ha dicho que el ordenamiento puede efectuarse moviendo los registros
con las claves. El mover un registo completo implica un costo, el cual
se incrementa conforme sea mayor el tamaño del registro. Es por ello que
es deseable evitar al máximo el movimiento de los registros. Una
alternativa es el crear una tabla de referencias a los registros y mover
las referencias y no los datos.
A continuación se mostrarán los métodos de ordenamiento empezando por el
más sencillo y avanzando hacia los mas sofisticados
La eficiencia de los algoritmos se mide por el número de comparaciones e
intercambios que tienen que hacer, es decir, se toma n como el número
de elementos que tiene el arreglo a ordenar y se dice que un algoritmo
realiza O(n2) comparaciones cuando compara n veces los n elementos, n x n = n2.
ORDENAMIENTO DE BURBUJA
La Ordenación de burbuja (Bubble Sort en inglés) es un sencillo algoritmo de ordenamiento.
Funciona revisando cada elemento de la lista que va a ser ordenada con
el siguiente, intercambiándolos de posición si están en el orden
equivocado. Es necesario revisar varias veces toda la lista hasta que no
se necesiten más intercambios, lo cual significa que la lista está
ordenada. Este algoritmo
obtiene su nombre de la forma con la que suben por la lista los
elementos durante los intercambios, como si fueran pequeñas "burbujas".
También es conocido como el método del intercambio directo. Dado
que solo usa comparaciones para operar elementos, se lo considera un
algoritmo de comparación, siendo el más sencillo de implementar.
ORDENAMIENTO SHELLEl ordenamiento Shell (Shell sort en inglés) es un algoritmo de ordenamiento. El método se denomina Shell en honor de su inventor Donald Shell. Su implementación original, requiere O(n2)
comparaciones e intercambios en el peor caso. Un cambio menor
presentado en el libro de V. Pratt produce una implementación con un
rendimiento de O(n log2 n) en el peor caso. Esto es mejor que las O(n2) comparaciones requeridas por algoritmos simples pero peor que el óptimo O(n log n).
Aunque es fácil desarrollar un sentido intuitivo de cómo funciona este
algoritmo, es muy difícil analizar su tiempo de ejecución.El algoritmo Shell sort mejora el ordenamiento por inserción comparando
elementos separados por un espacio de varias posiciones. Esto permite
que un elemento haga "pasos más grandes" hacia su posición esperada. Los
pasos múltiples sobre los datos se hacen con tamaños de espacio cada
vez más pequeños. El último paso del Shell sort es un simple
ordenamiento por inserción, pero para entonces, ya está garantizado que
los datos del vector están casi ordenados.
#include<stdio.h>
#include<conio.h>
int a[5];
int n=5;
void main()
{
int inter=(n/2),i=0,j=0,k=0,aux;
clrscr();
for (i=0; i<5; i++)
{
printf("INSERTA UN VALOR DEL INDICE %d", i);
scanf("%d",& a);
}
while(inter>0){
for(i=inter;i<n;i++)
{
j=i-inter;
while(j>=0) {
k=j+inter;
if(a[j]<=a[k]){
j--;
}
else{
aux=a[j];
a[j]=a[k];
a[k]=aux;
j=j-inter;
}
}
}
inter=inter/2;
}
for(i=0;i<5;i++)
{
printf("%d n",a);
getch();
}
} ORDENAMIENTO POR INSERCION
El ordenamiento por inserción (insertion sort en inglés)
es una manera muy natural de ordenar para un ser humano, y puede usarse
fácilmente para ordenar un mazo de cartas numeradas en forma
arbitraria. Requiere O(n²) operaciones para ordenar una lista de n
elementos.
Inicialmente se tiene un solo elemento, que obviamente es un conjunto ordenado. Después, cuando hay k elementos ordenados de menor a mayor, se toma el elemento k+1
y se compara con todos los elementos ya ordenados, deteniéndose cuando
se encuentra un elemento menor (todos los elementos mayores han sido
desplazados una posición a la derecha) o cuando ya no se encuentran
elementos (todos los elementos fueron desplazados y este es el más
pequeño). En este punto se inserta el elemento k+1 debiendo desplazarse los demás elementos.
iinserccion #include<stdio.h>
#include<conio.h>
int a[4]={4,1,7,2};
int n=4;
int i,j,aux;
void main(){
clrscr();
for(i=1;i<n;i++)
{
j=i;
aux=a;
while(j>0 && aux<a[j-1])
{
a[j]=a[j-1];
j--;
}
a[j]=aux;
}
for(i=0;i<4;i++)
{
printf("%d",a);
}
getch();
}
ORDENAMIENTO POR SELECCION El ordenamiento por selección (Selection Sort en inglés) es un algoritmo de ordenamiento que requiere O operaciones para ordenar una lista de n elementos. Su funcionamiento es el siguiente:
Buscar el mínimo elemento de la lista
Intercambiarlo con el primero
Buscar el mínimo en el resto de la lista
Intercambiarlo con el segundo
Y en general:
Buscar el mínimo elemento entre una posición i y el final de la lista
Intercambiar el mínimo con el elemento de la posición i
De esta manera se puede escribir el siguiente pseudocódigo para ordenar una lista de n elementos indexados desde el 1:
para i=1 hasta n-1
minimo = i;
para j=i+1 hasta n
si lista[j] < lista[minimo] entonces
minimo = j /* (!) */fin sifin para
intercambiar(lista[i], lista[minimo])
fin para
seleccion #include<stdio.h>
#include<conio.h>
int x[4]={1,4,8,6};
int n=4,j=0,i=0;
int temp=0,minimo=0;
void main(){
clrscr();
for(i=0;i<n-1;i++)
{
minimo=i;
for(j=i+1;j<n;j++)
{
if(x[minimo] > x[j])
{
minimo=j;
}
}
temp=x[minimo];
x[minimo]=x;
x=temp;
}
for(i=0;i<n;i++)
{
printf("%d",x);
}
getch();
}EJERCICIOS METODO DE ORDENAMIENTOEJERCICIO 01
#include <stdio.h>
#define SIZE 7
void main(void) {
int vector[SIZE];
int j, i, temp;
printf("Introduce los %d valores para ordenar:
", SIZE);
for(i=0; i<SIZE; i++) {
printf("%d: ", i+1);
scanf("%d", &vector[i]);
printf("
");
}
/* se aplica el algoritmo de la burbuja */
for(i=0; i<(SIZE-1); i++) {
for (j=i+1; j<SIZE; j++) {
if(vector[j]<vector[i]) {
temp=vector[j];
vector[j]=vector[i];
vector[i]=temp;
}
}
}
printf("El vector ordenado es:
");
for(i=0; i<SIZE ; i++) {
printf("%d ", vector[i]);
}
printf("
");
}
EJERCIO 02
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
void OrdenaBurbuja (float v[], int n)
{
int t, h, e;
for (h=1; h<n; h++)
{
for(e=0; e<n;e++)
{
if (v[e]>v[e+1])
{
v[e+1] = t;
v[e] = v[e+1];
t= v[e];
}
}
}
}
void ImprimirVector(float v[], int n)
{
int i;
for (i=0; i<n; i++)
{
printf("%f ", v[i]);
}
}
int main(int argc, char *argv[])
{
if(strcmp(argv[1], "burbuja")==0)
{
int n, i, m=2, o;
float *v;
{
n=argc-2;
v =(float *)malloc(n*sizeof(float));
for (i=0; i<n; i++)
{
v[i] = atof(argv[i+2]);
}
}
OrdenaBurbuja(v, n);
ImprimirVector(v, n);
}
system("PAUSE");
return 0;
}
Algoritmo de ordenamiento Shell: El método se denomina así en
honor de su inventor Donald Shell. Su implementación original, requiere
O(n2) comparaciones e intercambios en el peor caso, aunque un cambio
menor presentado en el libro de V. Pratt produce una implementación con
un rendimiento de O(n log2 n) en el peor caso. Esto es mejor que las
O(n2) comparaciones requeridas por algoritmos simples pero peor que el óptimo O(n log n).
El Shell sort es una generalización del ordenamiento por inserción, teniendo en cuenta dos observaciones:
El ordenamiento por inserción es eficiente si la entrada está "casi ordenada".
El ordenamiento por inserción es ineficiente, en general, porque mueve los valores sólo una posición cada vez.
El algoritmo Shell sort mejora el ordenamiento por inserción
comparando elementos separados por un espacio de varias posiciones. Esto
permite que un elemento haga "pasos más grandes" hacia su posición
esperada. Los pasos múltiples sobre los datos se hacen con tamaños de
espacio cada vez más pequeños. El último paso del Shell sort es un
simple ordenamiento por inserción, pero para entonces, ya está
garantizado que los datos del vector están casi ordenados.
Descripción
El algoritmo Shell es una mejora de la ordenación por inserción,
donde se van comparando elementos distantes, al tiempo que se los
intercambian si corresponde. A medida que se aumentan los pasos, el
tamaño de los saltos disminuye; por esto mismo, es útil tanto como si
los datos desordenados se encuentran cercanos, o lejanos.
Es bastante adecuado para ordenar listas de tamaño moderado,
debido a que su velocidad es aceptable y su codificación es bastante
sencilla. Su velocidad depende de la secuencia de valores con los cuales
trabaja, ordenándolos.El siguiente ejemplo muestra el proceso de forma
gráfica:
Considerando un valor pequeño que está inicialmente almacenado en
el final del vector. Usando un ordenamiento O(n2) como el ordenamiento
de burbuja o el ordenamiento por inserción, tomará aproximadamente n
comparaciones e intercambios para mover este valor hacia el otro extremo
del vector.
El Shell sort primero mueve los valores usando tamaños de espacio
gigantes, de manera que un valor pequeño se moverá bastantes posiciones
hacia su posición final, con sólo unas pocas comparaciones e
intercambios.
Ejemplo
Por ejemplo, considere una lista de números como [13 14 94 33 82 25
59 94 65 23 45 27 73 25 39 10]. Si comenzamos con un tamaño de paso de
8, podríamos visualizar esto dividiendo la lista de números en una tabla
con 5 columnas. Esto quedaría así:
Entonces ordenamos cada columna, lo que nos queda:
Cuando lo leemos de nuevo como una única lista de números, obtenemos [
10 14 73 25 23 13 27 94 33 39 25 59 94 65 82 45 ]. Aquí, el 10 que
estaba en el extremo final, se ha movido hasta el extremo inicial.
Esta lista es entonces de nuevo ordenada usando un ordenamiento
con un espacio de 3 posiciones, y después un ordenamiento con un espacio
de 1 posición (ordenamiento por inserción simple).
Secuencia de espacios
La secuencia de espacios es una parte integral del algoritmo
Shell sort. Cualquier secuencia incremental funcionaría siempre que el
último elemento sea 1. El algoritmo comienza realizando un ordenamiento por inserción con espacio,
siendo el espacio el primer número en la secuencia de espacios.
Continua para realizar un ordenamiento por inserción con espacio para
cada número en la secuencia, hasta que termina con un espacio de 1.
Cuando el espacio es 1, el ordenamiento por inserción con espacio
es simplemente un ordenamiento por inserción ordinario, garantizando
que la lista final estará ordenada. La secuencia de espacios que fue
originalmente sugerida por Donald Shell debía comenzar con N / 2 y
dividir por la mitad el número hasta alcanzar 1.
Aunque esta secuencia proporciona mejoras de rendimiento
significativas sobre los algoritmos cuadráticos como el ordenamiento por
inserción, se puede cambiar ligeramente para disminuir más el tiempo
necesario medio y el del peor caso.
Quizás la propiedad más crucial del Shell sort es que los elementos
permanecen k-ordenados incluso mientras el espacio disminuye.
Se dice que un vector dividido en k subvectores esta k-ordenado
si cada uno de esos subvectores esta ordenado en caso de considerarlo
aislado. Por ejemplo, si una lista fue 5-ordenada y después 3-ordenada,
la lista está ahora no sólo 3-ordenada, sino tanto 5-ordenada como
3-ordenada. Si esto no fuera cierto, el algoritmo desharía el trabajo
que había hecho en iteraciones previas, y no conseguiría un tiempo de
ejecución tan bajo.
Análisis del Costo Computacional
Aunque es fácil desarrollar un sentido intuitivo de cómo funciona
este algoritmo, es muy difícil analizar su tiempo de ejecución.
Dependiendo de la elección de la secuencia de espacios, Shell sort tiene
un tiempo de ejecución en el peor caso de O(n2) (usando los incrementos
de Shell que comienzan con 1/2 del tamaño del vector y se dividen por 2
cada vez), O(n3 / 2) (usando los incrementos de Hibbard de 2k − 1),
O(n4 / 3) (usando los incrementos de Sedgewick de 9(4i) − 9(2i) + 1, o
4i + 1 + 3(2i) + 1), o O(nlog2n), y posiblemente mejores tiempos de
ejecución no comprobados. La existencia de una implementación O(nlogn)
en el peor caso del Shell sort permanece como una pregunta por resolver.
Implementación
A continuación se muestra el Ordenamiento Shell en algunos de los lenguajes de programación de alto nivel más usados:
C
//Ordenamiento por método ShellpublicstaticvoidshellSort(int[]a){for(intincrement=a.length/2;increment>0;increment=(increment==2?1:(int)Math.round(increment/2.2))){for(inti=increment;i<>for(intj=i;j>=increment&&a[j-increment]>a[j];j-=increment){inttemp=a[j];a[j]=a[j-increment];a[j-increment]=temp;}}}}
Es un algoritmo de ordenación interna muy sencillo pero muy ingenioso,
basado en comparaciones e intercambios, y con unos resultados
radicalmente mejores que los que se pueden obtener con el método de la
burbuja, el des elección directa o el de inserción directa.
Sin embargo, es necesario romper una lanza a favor del algoritmo
ShellSort, ya que es el mejor algoritmo de ordenación in-situ... es
decir, el mejor de aquellos en los que la cantidad de memoria adicional
que necesita -aparte de los propios datos a ordenar, claro está- es
constante, sea cual sea la cantidad de datos a ordenar. El algoritmo de
la burbuja, el de selección directa, el de inserción directa y el de
Shell son todos in-situ, y éste último, el de Shell, es el que mejor
resultados da, sin ninguna duda de todos ellos y sus posibles variantes.
El ShellSort es una mejora del método de inserción directa que se
utiliza cuando el número de elementos a ordenar es grande. El método se
denomina “shell” –en honor de su inventor Donald Shell – y también
método de inserción con incrementos decrecientes.
En el método de clasificación por inserción, cada elemento se compara
con los elementos contiguos de su izquierda, uno tras otro. Si el
elemento a insertar es más pequeño - por ejemplo -, hay que ejecutar
muchas comparaciones antes de colocarlo en su lugar definitivamente.
Shell modifico los saltos contiguos resultantes de las comparaciones por
saltos de mayor tamaño y con eso se conseguía la clasificación más
rápida. El método se basa en fijar el tamaño de los saltos constantes,
pero de más de una posición.
Considere un valor pequeño que está inicialmente almacenado en el final
del vector. Usando un ordenamiento O(n2) como el ordenamiento de burbuja
o el ordenamiento por inserción, tomará aproximadamente n comparaciones
e intercambios para mover este valor hacia el otro extremo del vector.
El Shell sort primero mueve los valores usando tamaños de espacio
gigantes, de manera que un valor pequeño se moverá bastantes posiciones
hacia su posición final, con sólo unas pocas comparaciones e
intercambios.
Uno puede visualizar el algoritmo Shell sort de la siguiente manera:
coloque la lista en una tabla y ordene las columnas (usando un
ordenamiento por inserción). Repita este proceso, cada vez con un número
menor de columnas más largas. Al final, la tabla tiene sólo una
columna.
Mientras que transformar la lista en una tabla hace más fácil
visualizarlo, el algoritmo propiamente hace su ordenamiento en contexto
(incrementando el índice por el tamaño de paso, esto es usando i +=
tamaño_de_paso en vez de i++).
Por ejemplo, considere una lista de números como [ 13 14 94 33 82 25 59
94 65 23 45 27 73 25 39 10 ]. Si comenzamos con un tamaño de paso de 8,
podríamos visualizar esto dividiendo la lista de números en una tabla
con 5 columnas. Esto quedaría así:
13 14 94 33 82
25 59 94 65 23
45 27 73 25 39
10
Entonces ordenamos cada columna, lo que nos da:
10 14 73 25 23
13 27 94 33 39
25 59 94 65 82
45
Cuando lo leemos de nuevo como una única lista de números, obtenemos:
Aquí, el 10 que estaba en el extremo final, se ha movido hasta el
extremo inicial. Esta lista es entonces de nuevo ordenada usando un
ordenamiento con un espacio de 3 posiciones, y después un ordenamiento
con un espacio de 1 posición (ordenamiento por inserción simple).
El Shell sort lleva este nombre en honor a su inventor, Donald Shell,
que lo publicó en 1959. Algunos libros de texto y referencias antiguas
le llaman ordenación "Shell-Metzner" por Marlene Metzner Norton, pero
según Metzner, "No tengo nada que ver con el algoritmo de ordenamiento, y
mi nombre nunca debe adjuntarse a éste."
A continuación veamos un ejemplo en Pseudo-Código Para el Método de Shell Sort
Ejemplo del Método de Ordenamiento Shell Sort en C
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace PruebaVector
{
classPruebaVector
{
privateint[] vector;
publicvoid Cargar()
{
Console.WriteLine("Metodo de Shell Sort");
Console.Write("Cuantos longitud del vector:");
string linea;
linea = Console.ReadLine();
int cant;
cant = int.Parse(linea);
vector = newint[cant];
for (int f = 0; f < vector.Length; f++)
{
Console.Write("Ingrese elemento "+(f+1)+": ");
linea = Console.ReadLine();
vector[f] = int.Parse(linea);
}
}
publicvoid Shell()
{
int salto = 0;
int sw = 0;
int auxi = 0;
int e = 0;
salto = vector.Length / 2;
while (salto > 0)
{
sw = 1;
while (sw != 0)
{
sw = 0;
e = 1;
while (e <= (vector.Length - salto))
{
if (vector[e - 1] > vector[(e - 1) + salto])
{
auxi = vector[(e - 1) + salto];
vector[(e - 1) + salto] = vector[e - 1];
vector[(e - 1)] = auxi;
sw = 1;
}
e++;
}
}
salto = salto / 2;
}
}
publicvoid Imprimir()
{
Console.WriteLine("Vector ordenados en forma ascendente");
Mail: backupenviotrabajos@gmail.com En AS.: 2021JVG PROG1 LUNES TT (su nombre y apellido)
En un mundo donde los cambios se suceden vertiginosamente, incluso los tecnológicos, es menester asimilar las nuevas tecnologías para su aplicación inmediata y su proyección a futuro.
Este será un canal de comunicación entre nosotros. Tendrá diferentes instancias dinamizadoras, y utilidades para trabajar los diferentes trabajos prácticos en diversas modalidades.

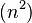 operaciones para ordenar una lista de n elementos.
operaciones para ordenar una lista de n elementos.


